Poster
Diffusion-SDF: Text-To-Shape via Voxelized Diffusion
Muheng Li · Yueqi Duan · Jie Zhou · Jiwen Lu
West Building Exhibit Halls ABC 028
{kind=link}
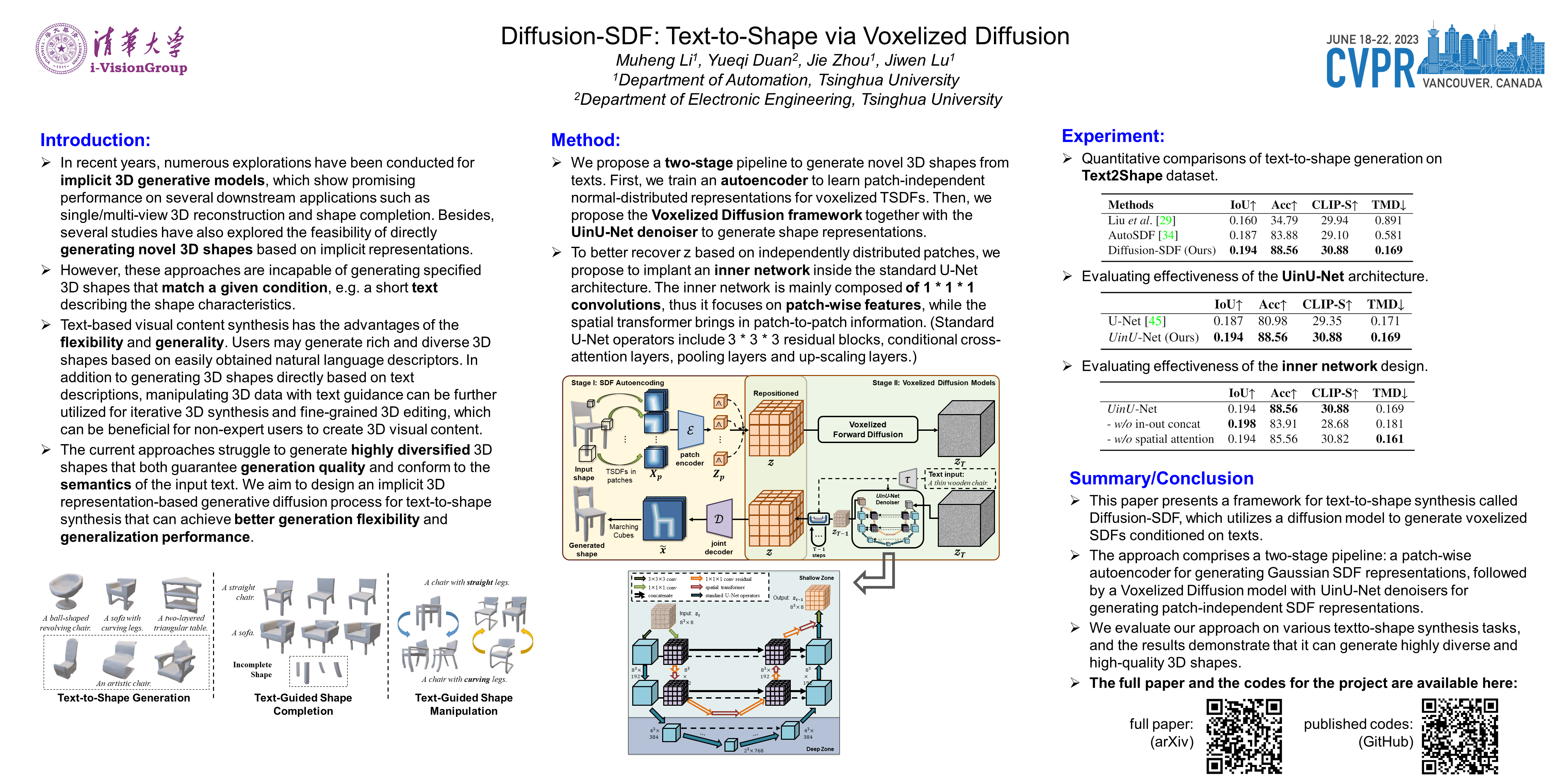
With the rising industrial attention to 3D virtual modeling technology, generating novel 3D content based on specified conditions (e.g. text) has become a hot issue. In this paper, we propose a new generative 3D modeling framework called Diffusion-SDF for the challenging task of text-to-shape synthesis. Previous approaches lack flexibility in both 3D data representation and shape generation, thereby failing to generate highly diversified 3D shapes conforming to the given text descriptions. To address this, we propose a SDF autoencoder together with the Voxelized Diffusion model to learn and generate representations for voxelized signed distance fields (SDFs) of 3D shapes. Specifically, we design a novel UinU-Net architecture that implants a local-focused inner network inside the standard U-Net architecture, which enables better reconstruction of patch-independent SDF representations. We extend our approach to further text-to-shape tasks including text-conditioned shape completion and manipulation. Experimental results show that Diffusion-SDF generates both higher quality and more diversified 3D shapes that conform well to given text descriptions when compared to previous approaches. Code is available at: https://github.com/ttlmh/Diffusion-SDF.