Poster
Identity-Preserving Talking Face Generation With Landmark and Appearance Priors
Weizhi Zhong · Chaowei Fang · Yinqi Cai · Pengxu Wei · Gangming Zhao · Liang Lin · Guanbin Li
West Building Exhibit Halls ABC 143
{kind=link}
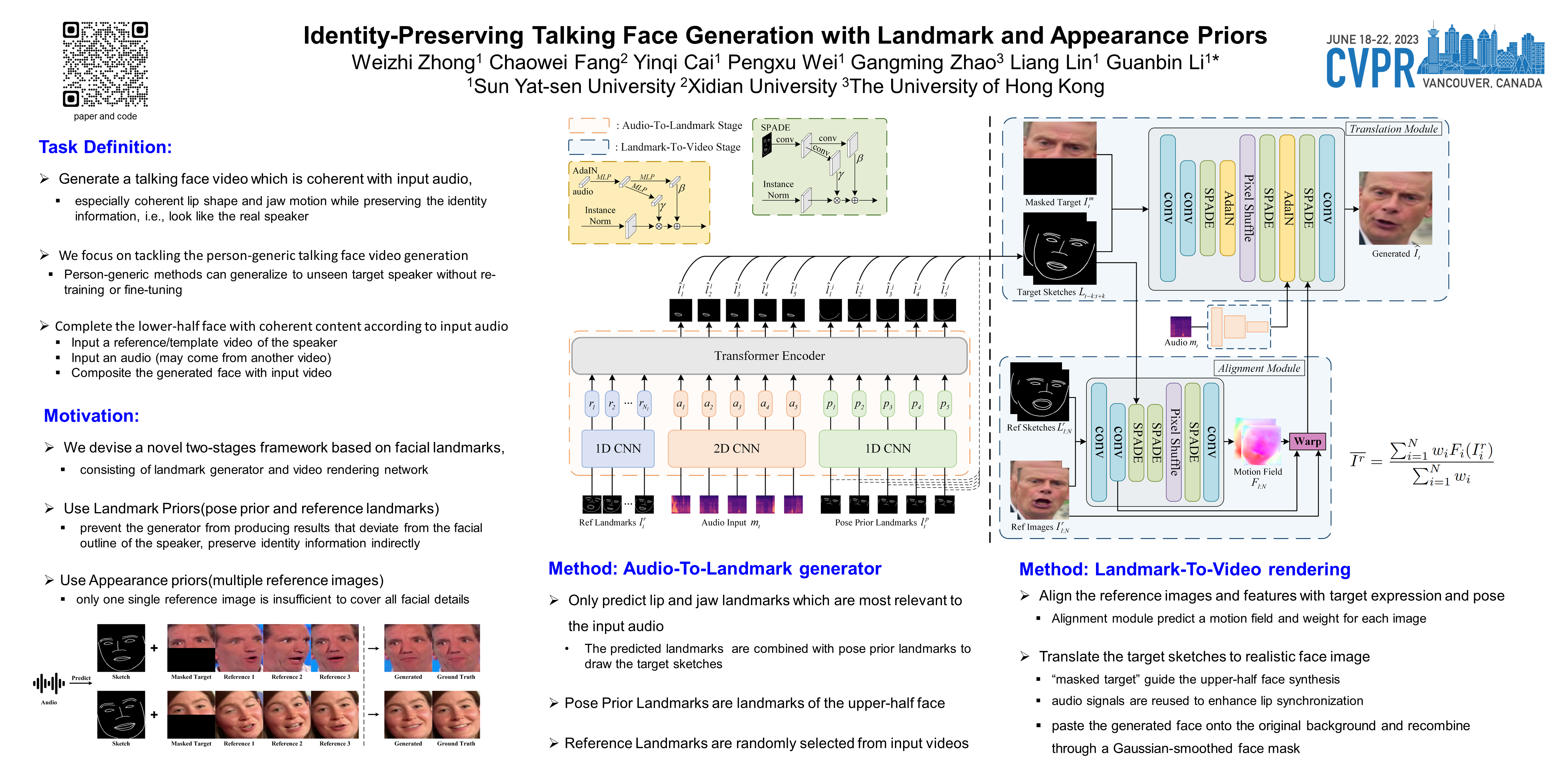
Generating talking face videos from audio attracts lots of research interest. A few person-specific methods can generate vivid videos but require the target speaker’s videos for training or fine-tuning. Existing person-generic methods have difficulty in generating realistic and lip-synced videos while preserving identity information. To tackle this problem, we propose a two-stage framework consisting of audio-to-landmark generation and landmark-to-video rendering procedures. First, we devise a novel Transformer-based landmark generator to infer lip and jaw landmarks from the audio. Prior landmark characteristics of the speaker’s face are employed to make the generated landmarks coincide with the facial outline of the speaker. Then, a video rendering model is built to translate the generated landmarks into face images. During this stage, prior appearance information is extracted from the lower-half occluded target face and static reference images, which helps generate realistic and identity-preserving visual content. For effectively exploring the prior information of static reference images, we align static reference images with the target face’s pose and expression based on motion fields. Moreover, auditory features are reused to guarantee that the generated face images are well synchronized with the audio. Extensive experiments demonstrate that our method can produce more realistic, lip-synced, and identity-preserving videos than existing person-generic talking face generation methods.