{kind=link}
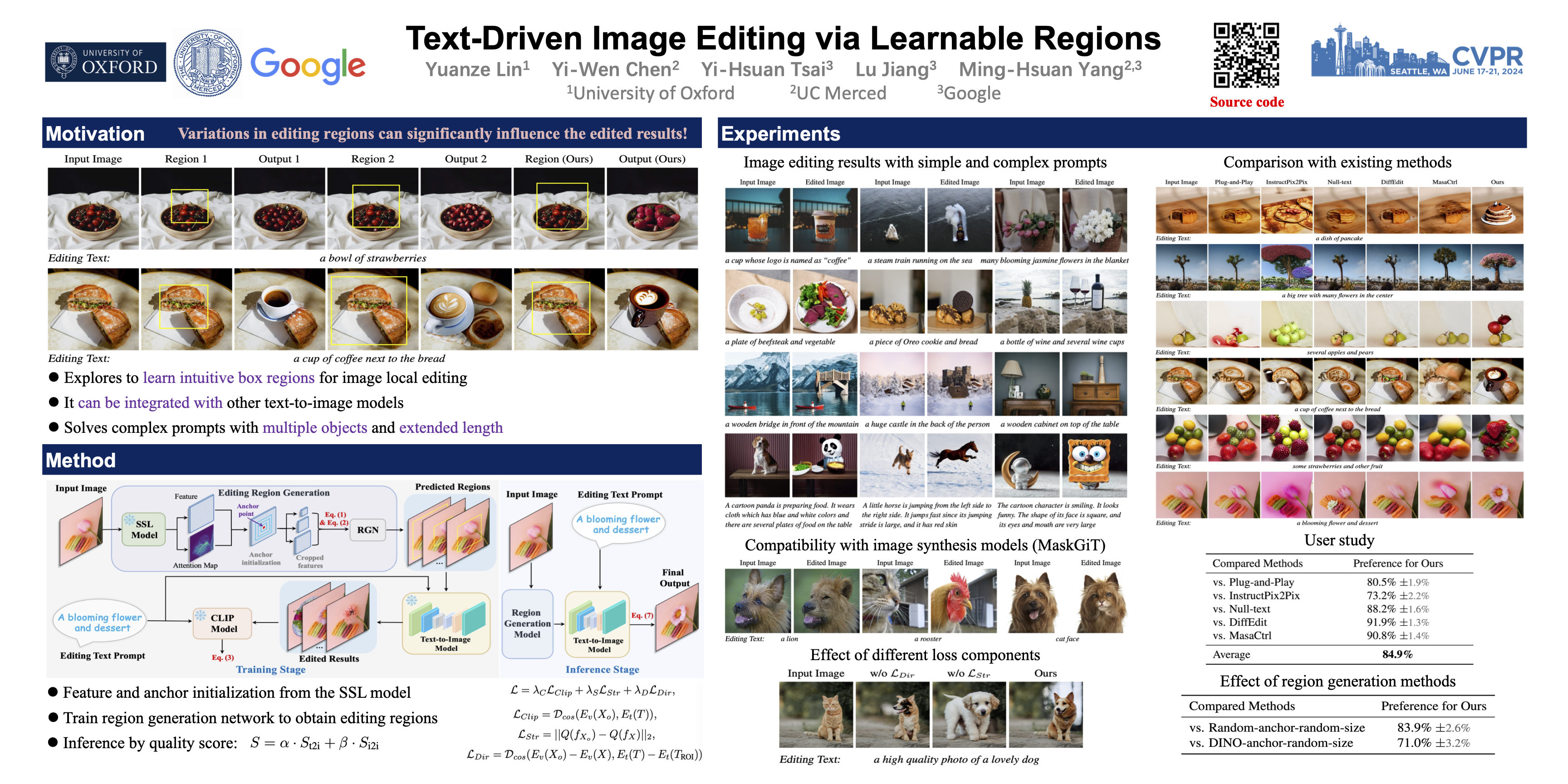
Language has emerged as a natural interface for image editing. In this paper, we introduce a method for region-based image editing driven by textual prompts, without the need for user-provided masks or sketches. Specifically, our approach leverages an existing pretrained text-to-image model and introduces a bounding box generator to find the edit regions that are aligned with the textual prompts. We show that this simple approach enables flexible editing that is compatible with current image generation models, and is able to handle complex prompts featuring multiple objects, complex sentences or long paragraphs. We conduct an extensive user study to compare our method against state-of-the-art baseline methods. Experiments demonstrate our method's competitive performance in manipulating images with high fidelity and realism that align with the language descriptions provided.