Poster
MELTR: Meta Loss Transformer for Learning To Fine-Tune Video Foundation Models
Dohwan Ko · Joonmyung Choi · Hyeong Kyu Choi · Kyoung-Woon On · Byungseok Roh · Hyunwoo J. Kim
West Building Exhibit Halls ABC 344
{kind=link}
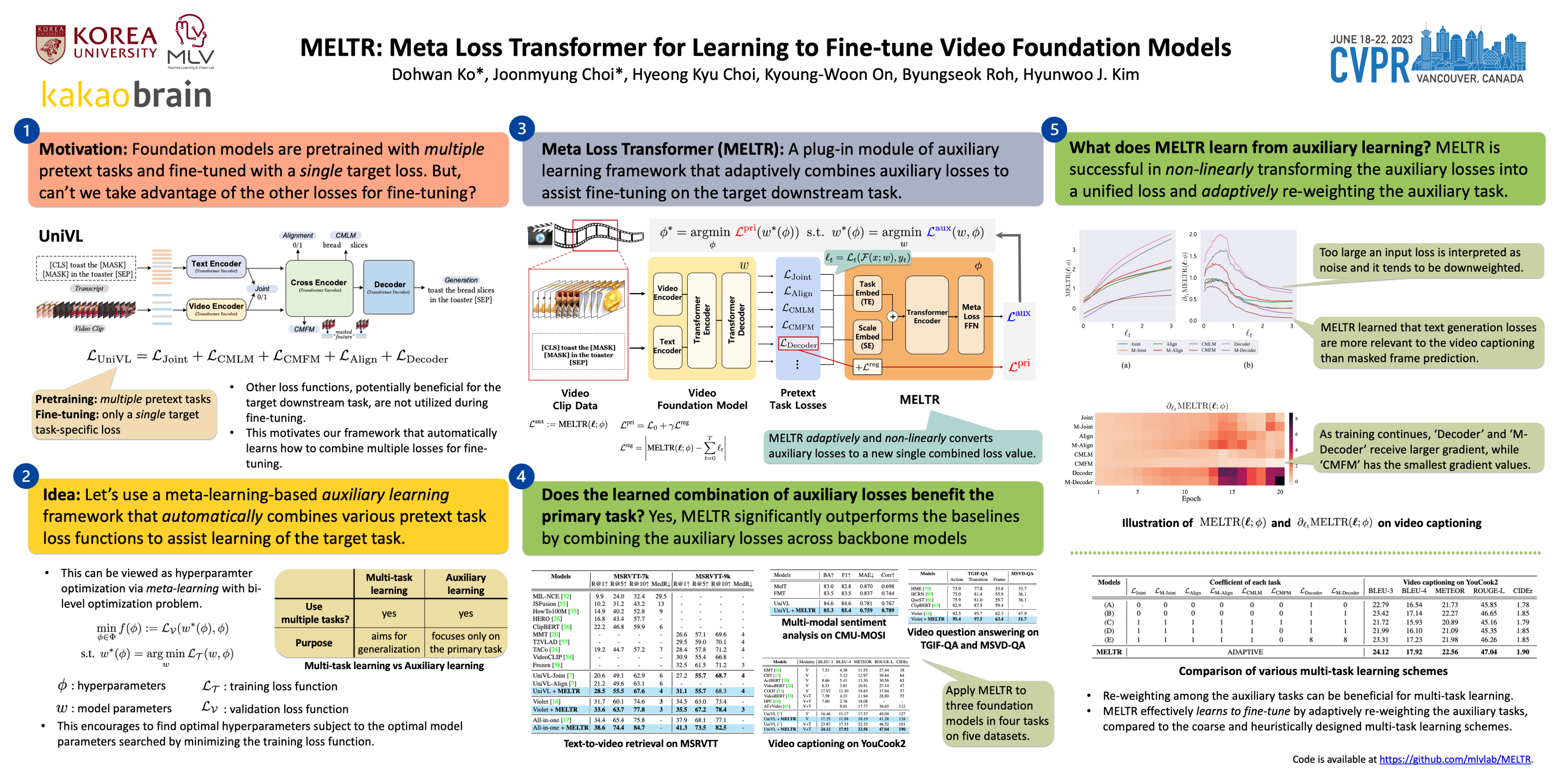
Foundation models have shown outstanding performance and generalization capabilities across domains. Since most studies on foundation models mainly focus on the pretraining phase, a naive strategy to minimize a single task-specific loss is adopted for fine-tuning. However, such fine-tuning methods do not fully leverage other losses that are potentially beneficial for the target task. Therefore, we propose MEta Loss TRansformer (MELTR), a plug-in module that automatically and non-linearly combines various loss functions to aid learning the target task via auxiliary learning. We formulate the auxiliary learning as a bi-level optimization problem and present an efficient optimization algorithm based on Approximate Implicit Differentiation (AID). For evaluation, we apply our framework to various video foundation models (UniVL, Violet and All-in-one), and show significant performance gain on all four downstream tasks: text-to-video retrieval, video question answering, video captioning, and multi-modal sentiment analysis. Our qualitative analyses demonstrate that MELTR adequately ‘transforms’ individual loss functions and ‘melts’ them into an effective unified loss. Code is available at https://github.com/mlvlab/MELTR.